
For countless IT administrators across North America, the workday began not with a routine check of systems but with a digital wall, as the central nervous system of Microsoft 365 suddenly and inexplicably went offline.
The Critical Hub Goes Dark Understanding the Admin Center Disruption
A significant service disruption recently struck the heart of Microsoft 365, leaving countless business and enterprise administrators across North America unable to access their primary management portal. The M365 admin center is the nerve center for IT professionals, used for everything from managing user accounts and security policies to monitoring service health. When it goes down, the ability to manage and support an organization’s digital infrastructure is severely compromised. This timeline will chronicle the key events of the outage, from the first user reports to Microsoft’s final resolution, providing crucial context on the event’s impact and its place within a broader pattern of service reliability challenges.
A Timeline of the North American Outage
Early Morning The Portal Locks Down
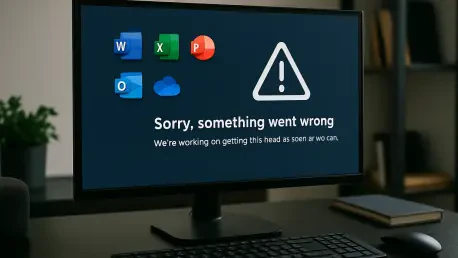
The first signs of trouble emerged as administrators across North America began their workday, only to find themselves locked out of the Microsoft 365 admin center. Widespread connection problems were quickly corroborated by thousands of user reports on outage-tracking sites like DownDetector. For the few who could gain intermittent access, the service was severely degraded, with the portal operating at an extremely slow pace. Critically, this degradation also prevented many from filing official support tickets through the expected channels, leaving them isolated and without a direct line to Microsoft for assistance. The M365 app’s functionality was also reported to be affected, compounding the issue for admins on the move.
Mid Day Microsoft Launches an Investigation
As reports mounted, Microsoft officially acknowledged the issue on its service health status page, classifying it as an “incident”—a designation indicating a noticeable and impactful service problem. The company’s engineering teams immediately launched a thorough investigation to isolate the root cause of the access and performance issues. Their multi-pronged analysis involved a deep dive into service monitoring telemetry and a close review of diagnostic data, with a specific focus on Central Processing Unit (CPU) utilization levels and usage patterns that might indicate a system under strain. To gain further insight, engineers also began examining HTTP Archive (HAR) files provided by impacted users to better understand the client-side experience during the failure.
Late Afternoon A Return to Normalcy
After several hours of investigation and mitigation efforts, Microsoft reported that the issue had been resolved. The company confirmed that access to the M365 admin center was restored and its performance had returned to normal levels. This confirmation came from a combination of the company’s internal service monitoring, which showed health metrics returning to baseline, and positive reports from customers who were finally able to access the portal without issue. With services stabilized, the immediate crisis concluded, allowing administrators to resume their essential management and support functions.
Key Takeaways from the Admin Center Failure
The most significant turning point in this event was Microsoft’s shift from initial acknowledgment to a deep technical investigation focusing on CPU utilization and telemetry data, suggesting the problem was not a simple network glitch but a core processing issue. This incident highlights a recurring theme for cloud service subscribers: the vulnerability of centralized management platforms. When the single pane of glass for administration shatters, even temporarily, it creates a significant operational blind spot. While service was restored, the incident underscores the need for clear and rapid communication from providers, as the initial inability for admins to even file a support ticket was a major point of frustration.
Placing the Outage in a Wider Context
This admin center outage does not exist in a vacuum. It follows other high-profile service disruptions, including a critical login issue that impacted users over a year ago and a similar admin portal failure in July 2023 that generated “Runtime Error” messages for administrators. While unrelated in its root cause, a recent power outage at a data center that briefly took down the Microsoft Store and Windows Update services further illustrates the various stress points within a massive cloud ecosystem. These repeated incidents emphasized the complex challenge of maintaining near-perfect uptime and the cascading impact that even a regional, component-specific failure could have on businesses who had placed their trust and critical operations in the cloud.